Stills




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Features
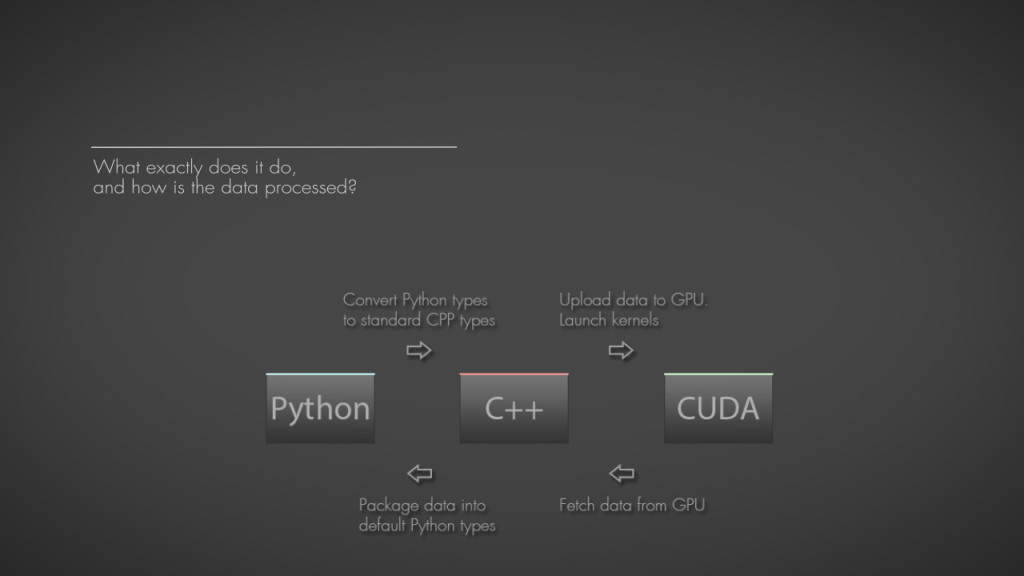
- Process Python types (lists etc.) in parallel on the GPU.
- DCC agnostic.
- Accelleration structures for minimized uploading to GPU memory.
Details
- Wrapping: Boost Python
- Python Version: 2.6×64, 2.7×64
- CUDA: 5.5
- Maya Versions: 2012, 2013, 2013.5, 2014
Disclaimer
This is just a test or proof of concept i have done to dive a little deeper into the Python C API, and is not ment to be a production solution or evolve into a serious project. It’s just fun to toy around with and a great excercise.
Known issues
Extracting data out of Python types and packaging them again is not threadsafe and therefore has to be done serial. That is a major limiting factor, and a big hit for performance. Im not sure if there is any way to speed this up? Ideas or suggestions are welcome!